The use of AI agents is rapidly expanding across enterprise systems, driving new levels of automation, decision-making, and intelligent interaction. However, this evolution also introduces complexity in managing agent behavior, data access, and real-time responses within operational environments. To ensure AI agents act responsibly, comply with organizational policies, and maintain reliability and trust in AI-driven workflows, establishing robust guardrails is essential.
This guide provides a comprehensive framework for developing policy, configuration, and runtime guardrails, enabling control, transparency, and compliance without limiting innovation.
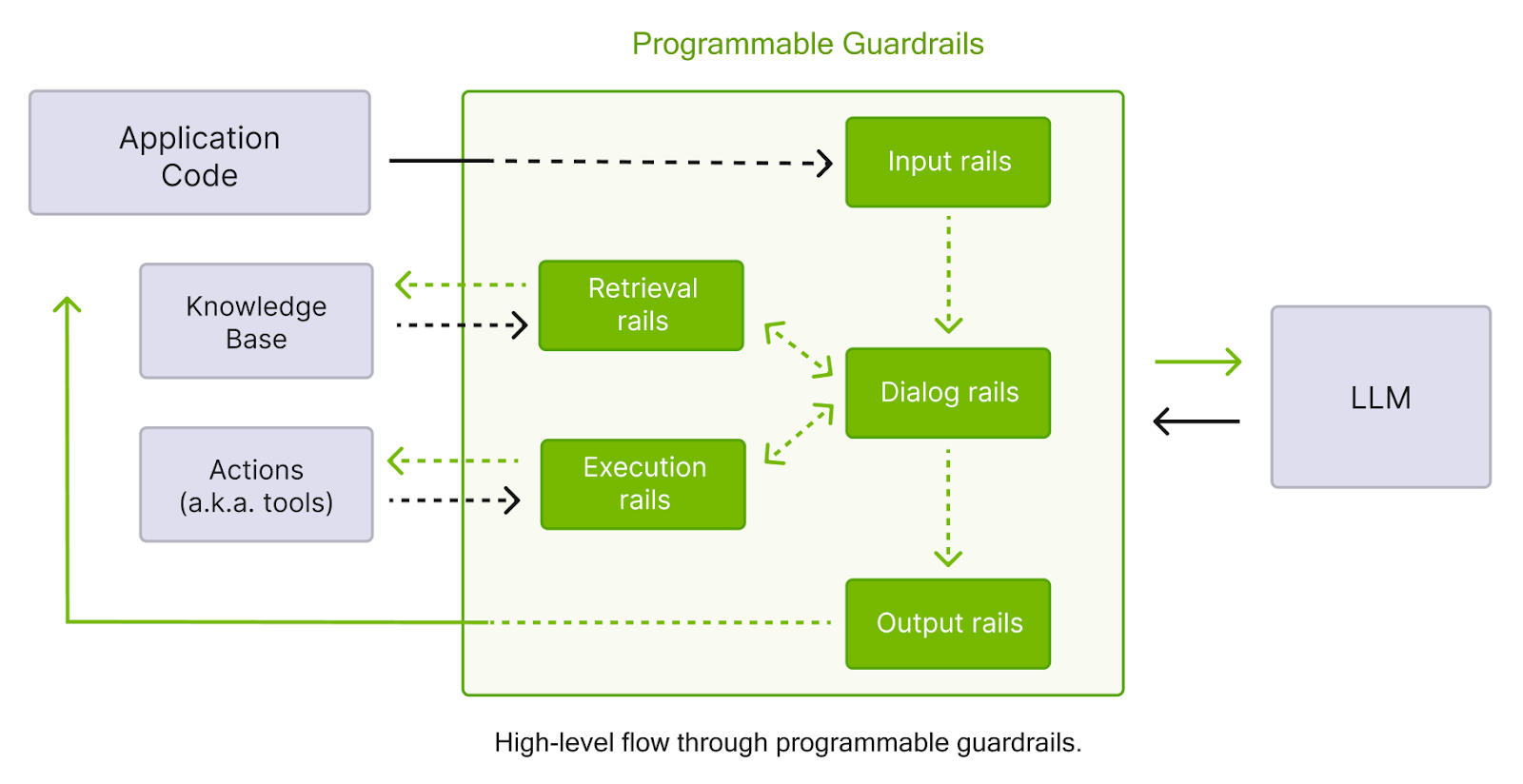
Guardrails are the limits and checks that the AI agent is subjected to so that its operation is always predictable, safe, and compliant. The controls can be technical, operational, and policy-based, which will define the range of actions the agent can take, its manner of interaction with the systems, and the end results of the interactions he/she has with them.
The installation of guardrails is not aimed at limiting the capacity of the AI agent but rather at setting up a framework within which the actions are deliberate, measurable, and reversible. The goal is to ensure every action or decision made by an AI agent aligns with company policies, ethical standards, and data-handling regulations.
Before defining guardrails, it’s essential to understand the different types of AI agents- autonomous, semi-autonomous, and assisted - as each requires a distinct level of control and supervision. While fully autonomous agents demand multiple safeguards along the decision logic, external integrations, and system permissions, semi-autonomous agents can be allowed to use more policy-based supervision and approval mechanisms.

Policy guardrails define the framework for acceptable AI agent behavior and are typically implemented at the organizational level. These policies set the boundaries for what agents can access, the type of data they can process, and the decisions they are authorized to make.
AI agents often access sensitive internal or external data sources. A well-defined data policy ensures they operate within privacy and compliance boundaries:
Data access policies should also include PII masking rules and redaction configurations for input and output prompts to prevent data leakage during reasoning. These policies should integrate with enterprise DLP (Data Loss Prevention) and CSPM (Cloud Security Posture Management) tools to automate enforcement.
Organizations must specify autonomy thresholds that determine how far agents can act without human intervention. Examples:
Decision boundaries can also be reinforced through a risk scoring system, where actions exceeding a certain confidence or impact threshold trigger review.
Compliance guardrails align agents with internal audit standards and external regulatory frameworks such as HIPAA, GDPR, or SOC 2. Policies should:
Policies must clearly define interaction boundaries - what kind of users or systems the agent can communicate with, and how it handles escalations or exceptions. Examples:
Policy-level guardrails create a governance foundation. Translating them into enforceable technical configurations is the next step.
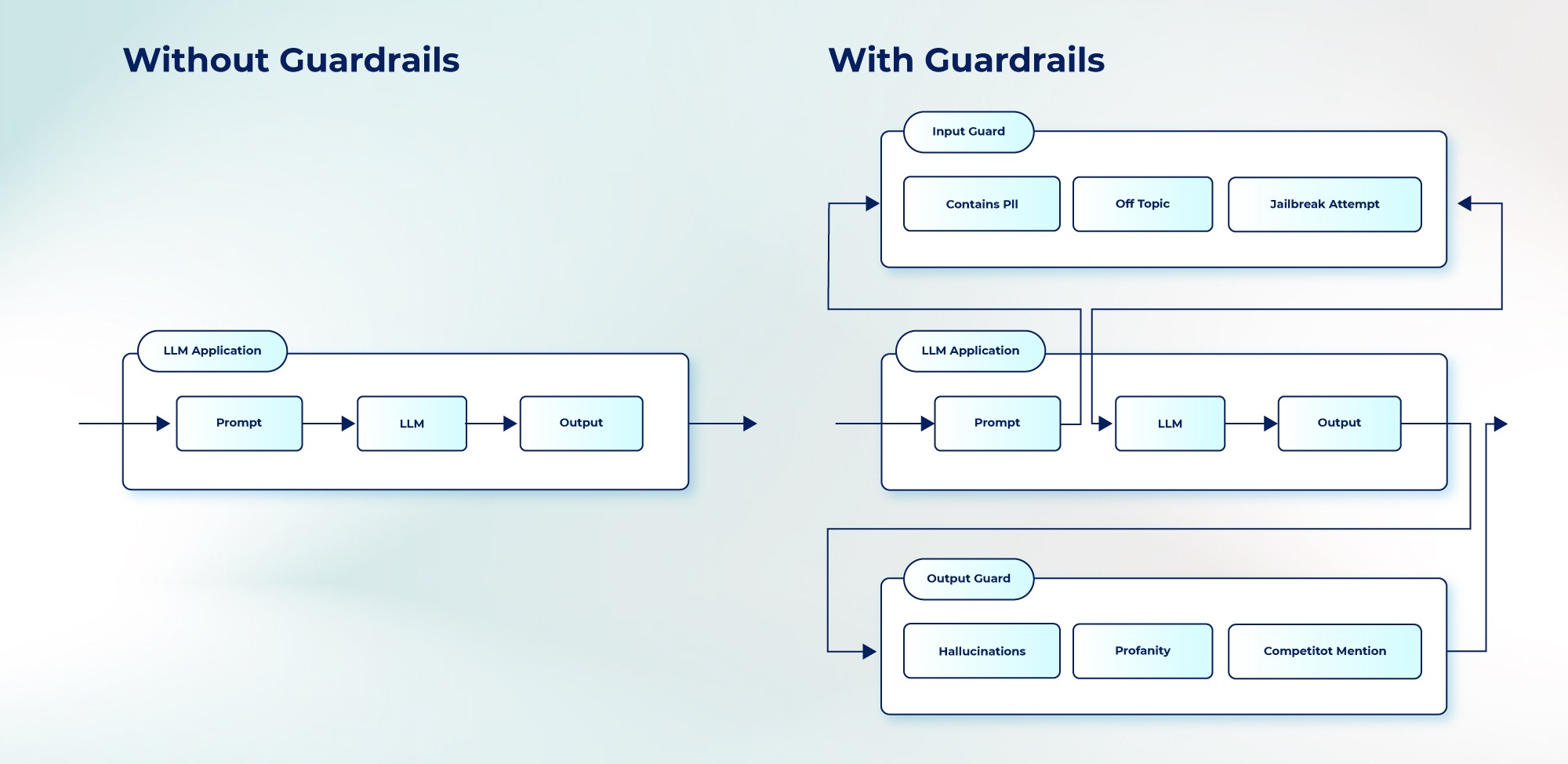
Configuration-level guardrails enforce policies at the system and runtime level. These controls define operational boundaries through permissions, workflow constraints, and runtime enforcement mechanisms.
Every AI agent should be treated as a service identity within the enterprise identity and access management (IAM) system. This enables consistent enforcement of:
Additionally, session scoping can ensure that temporary tasks performed by the agent are time-limited and revoked automatically after task completion.
Prompt control is a critical layer for avoiding model misuse or prompt injection attacks. Guardrails should include:
Prompt logs should be stored in structured formats for observability and auditing, with automated masking or tokenization of sensitive data.
Agents that execute tasks, such as sending emails, modifying records, or running scripts, must operate within sandboxed environments. Sandboxing isolates the agent’s runtime and prevents access beyond defined APIs or resources.
Configurations should include:
Task-level guardrails are particularly important for multi-agent orchestration systems, where one agent’s action may trigger workflows across others.
Governance extends to how models and configurations are managed over time. A centralized model registry should track:
Change management workflows must require formal approvals before updating model configurations or deploying new versions, ensuring traceability and rollback capability. Integration with CI/CD pipelines allows automatic validation of configuration drift against policy baselines.
Agents often integrate with external systems through APIs or message brokers. To avoid the uncontrolled expansion of their operational scope:
When interacting with third-party APIs, ensure that data sharing agreements and encryption standards align with enterprise compliance policies.

Even with strong policies and configurations, runtime monitoring is essential to detect and respond to anomalies in real time. Guardrails at this layer act as the last line of defense, ensuring the agent behaves as expected in production environments.
Set up observability dashboards that track:
Monitoring should integrate with enterprise observability platforms such as Grafana, Prometheus, or Datadog to maintain unified visibility across environments.
Machine learning-based anomaly detection can help identify deviations in agent behavior, such as unexpected request patterns, unauthorized API calls, or abnormal data queries. Define baseline behavior profiles for each agent type and configure alerts to trigger when metrics deviate significantly from expected patterns.
This layer of monitoring not only protects against malicious or erroneous actions but also supports continuous improvement by identifying where guardrails might need tightening or relaxing.
Every agent decision, prompt, and output should be traceable through a structured audit trail. Ensure that:
This level of traceability is often a regulatory requirement and also forms the foundation for root cause analysis in case of incidents.
A well-defined incident response playbook must exist for AI agent failures or misbehavior. It should define:
Integrating guardrail alerts with enterprise incident management systems (e.g., ServiceNow or PagerDuty) ensures rapid detection, escalation, and remediation of policy breaches.
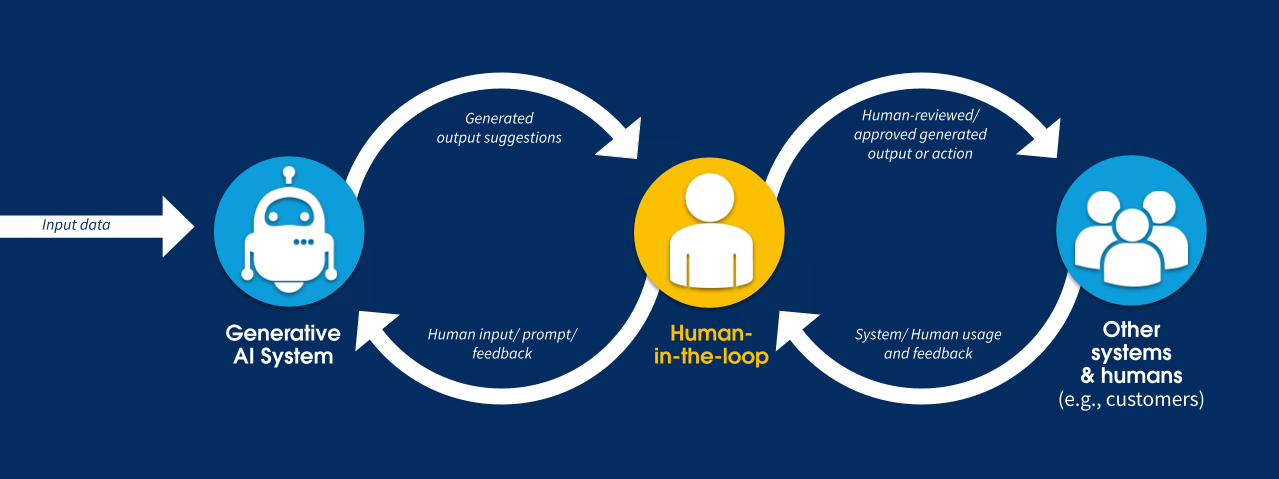
While automation is key to scaling, human oversight remains a critical safety control. Human-in-the-Loop (HITL) mechanisms can intervene at various stages depending on the risk profile of the task.
Agents handling sensitive or high-impact actions should automatically trigger human approval workflows:
Agent confidence scores can determine whether human intervention is needed. Actions below a set threshold can be paused for verification.
This hybrid approach allows organizations to benefit from automation without compromising accountability or control.
Implementing guardrails for AI agents is not a one-time task but an ongoing process that blends policy, configuration, and runtime enforcement. Effective guardrails combine governance principles with operational enforcement, ensuring that agents act responsibly, transparently, and within defined organizational boundaries.
By combining clear policies, configuration-level controls, real-time observability, and continuous governance, enterprises can scale AI agent deployments safely - balancing innovation, autonomy, and accountability across every operational layer.
Begin with a clear policy baseline that defines data, decision, and interaction boundaries.
Learn more in Reco’s CISO Guide to AI Security.
Define data classification, PII masking, and redaction policies at the enterprise level.
Explore best practices in Reco’s SaaS Compliance Learning Hub.
Reco uses policy-to-action pipelines that automate runtime enforcement and rollback.
Read the use case How Reco’s AI Agents Transform SaaS Security.
.svg)

.svg)











%201.svg)









.svg)