Deploying OpenAI’s API in production environments is fundamentally different from working with traditional APIs. Generative AI models accept unstructured, unpredictable inputs and generate outputs that can influence critical workflows, customer experiences, or even financial and regulatory decisions. This flexibility creates new opportunities for innovation, but also introduces novel risks that demand strong security.
Unlike static APIs, where inputs and outputs are tightly defined, generative systems are dynamic and adaptive. That very strength makes them a potential vector for misuse if not deployed carefully. From sensitive data being unintentionally exposed in prompts to models producing unsafe outputs, the risks extend beyond infrastructure security. Enterprises must therefore approach OpenAI deployment with the mindset of building a multi-layered defense, treating security as a continuous practice rather than a one-time checklist.

API keys act as the front door to OpenAI’s systems. If these credentials are mishandled or leaked, attackers can exploit them to consume quotas, trigger billing fraud, or access enterprise data pipelines. Securing keys is therefore the very first - and arguably most critical - step in building safe integrations.
Always store API keys in enterprise-grade secret managers such as AWS Secrets Manager, HashiCorp Vault, Azure Key Vault, or GCP Secret Manager. These systems provide encryption at rest, role-based access controls, and audit logging. Avoid ad hoc methods like .env files or configuration hardcoding.
Keys must never appear in source code, Git repositories, or client-side environments like browser JavaScript or mobile apps. Hardcoded credentials are one of the most common ways attackers gain entry into production systems. Instead, load keys dynamically from secure storage at runtime.
Instead of reusing one global key across all environments, create environment-specific credentials (dev, staging, prod). This limits exposure, helps isolate suspicious behavior, and allows for more granular monitoring and quota enforcement.
It is advisable to have automated key rotation policies, ideally over a 60–90-day period. Rotation shortens the window of exposure for whatever time a key remains compromised. A key should be revoked at once in case of a leak or suspicious usage. Automate the rotation to be carried out in CI/CD pipelines or using secret orchestration tools to ensure consistency and eliminate human error.
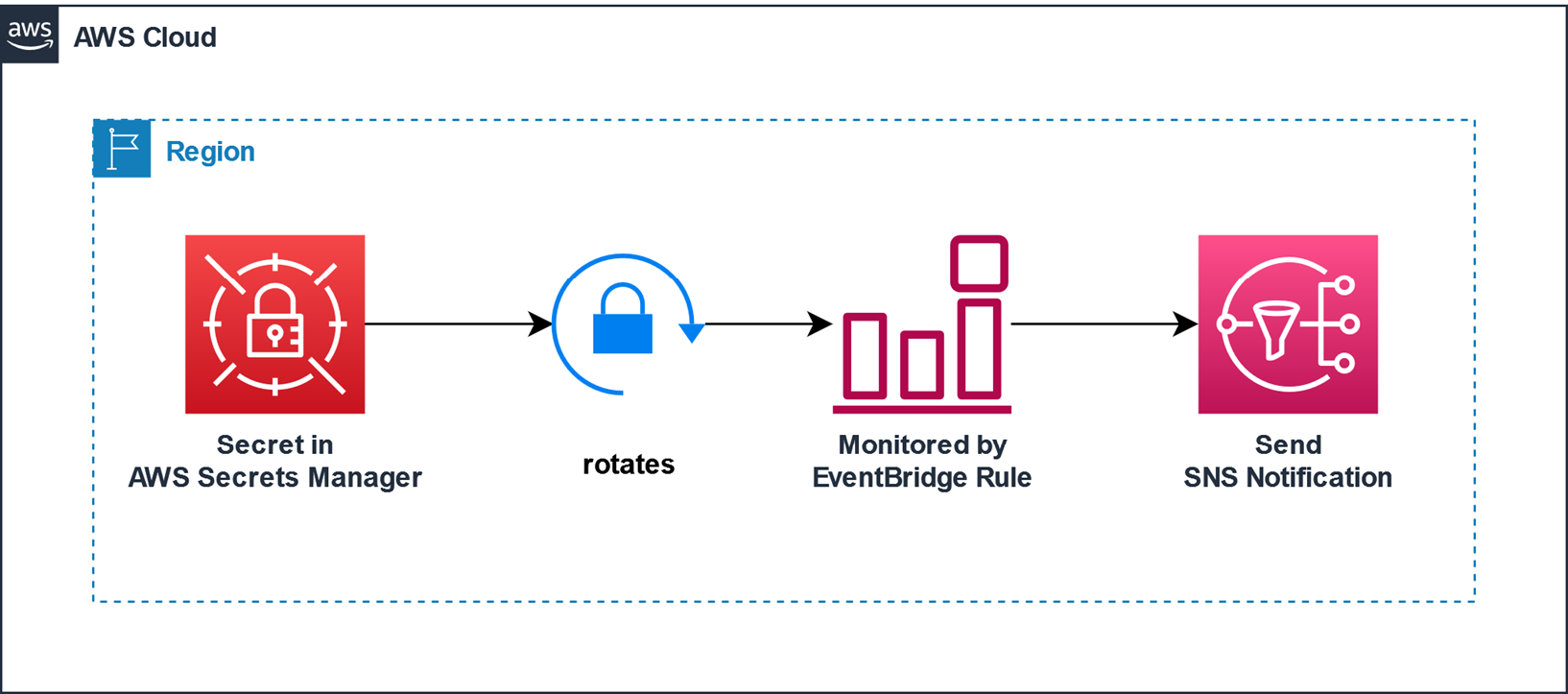
Consider the least privilege model when deciding on credentials. Separate keys should be used for different services under teams or applications instead of allowing them all to share one master credential. For instance, analytics pipelines should not share the same key as customer-facing applications. Doing so would help reduce the blast radius of compromises and make monitoring far more effective.
Once credentials are protected, the next line of defense is controlling where and how API traffic flows. OpenAI integrations should be isolated, monitored, and routed through secure pathways to prevent both accidental and malicious misuse.
Prompts are where business logic, user intent, and sensitive data intersect, making them one of the most exploited attack vectors. Malicious inputs can override system instructions, inject harmful commands, or trick the model into leaking restricted content. Building structured defenses around prompts is essential.

Data Privacy and Compliance for OpenAI / Azure OpenAI service
AI adoption intersects heavily with regulatory obligations. Enterprises must ensure that sensitive or regulated data flowing through OpenAI aligns with frameworks like GDPR, HIPAA, and SOC 2. Compliance not only protects against penalties but also builds customer trust in how AI is used.
Left unchecked, API misuse can quickly exhaust quotas, degrade service reliability, or inflate costs. Rate-limiting strategies ensure fair, predictable consumption of resources across different users and applications.
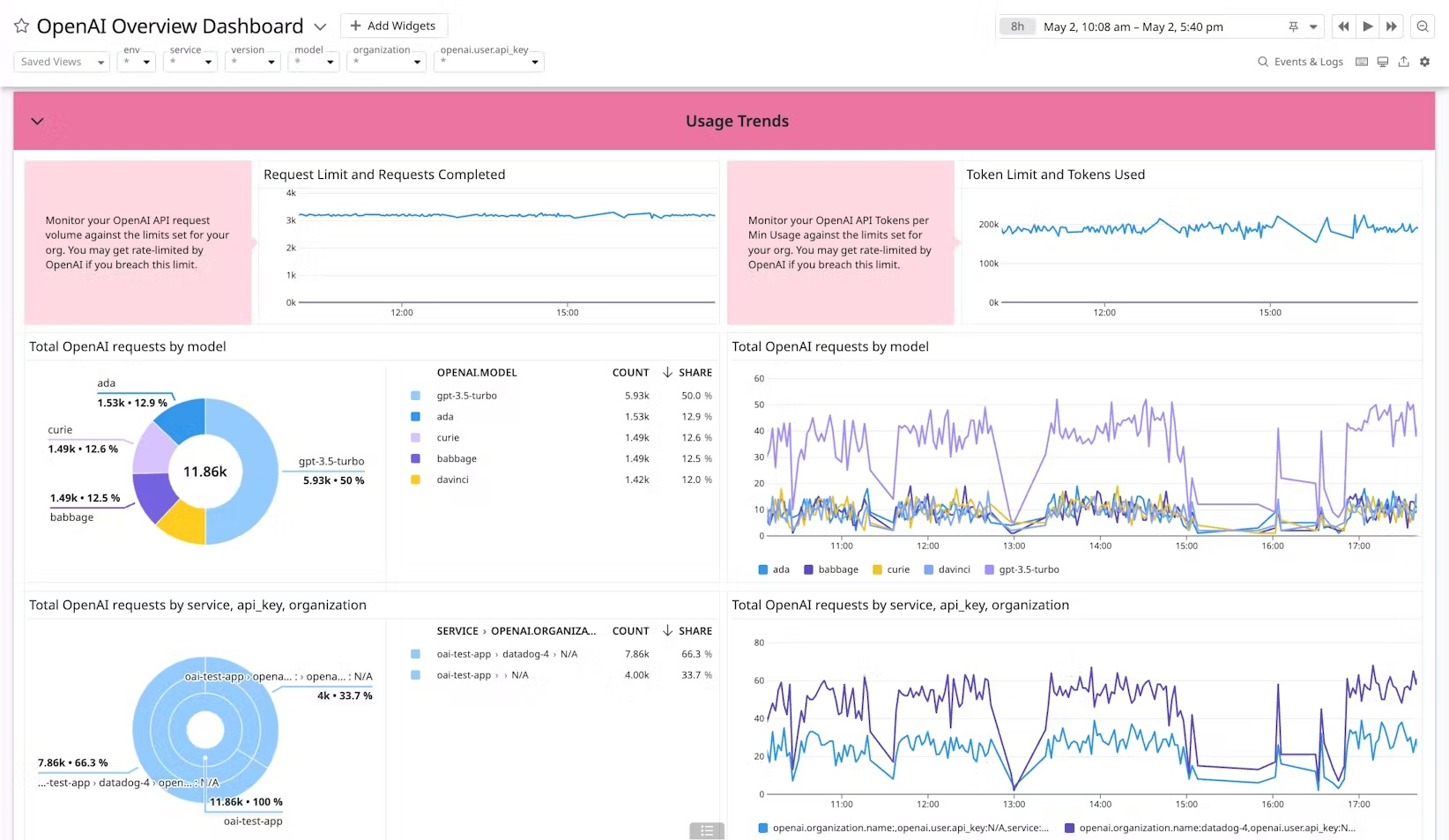
Strong visibility underpins every other security control. Without centralized logs and monitoring, enterprises cannot trace suspicious activity or prove compliance. Logs should be designed to capture operational insights while minimizing exposure of sensitive information.
Structured logging ensures that every API interaction produces metadata that is standardized, machine-readable, and easy to query. Capturing details such as request IDs, timestamps, token counts, response codes, and latency not only helps with troubleshooting but also supports compliance reporting and performance monitoring. By keeping logs in a structured format like JSON, organizations can automate queries and integrate them seamlessly with monitoring pipelines. This practice makes it far easier to detect anomalies and trends across large volumes of OpenAI API traffic.
Prompts and outputs may include sensitive or regulated information, so strict controls are required to avoid logging them in raw form. Instead, enterprises should implement redaction, hashing, or tokenization mechanisms to strip or anonymize personally identifiable information (PII) while preserving the ability to track patterns and usage. This reduces compliance risks under frameworks like GDPR and HIPAA while still providing security teams with actionable insights. Balancing privacy with visibility ensures that monitoring remains both ethical and effective.
Without centralization, logs often remain siloed within individual applications or services, making it difficult to detect cross-system patterns of abuse or compromise. By aggregating logs into enterprise SIEMs or observability platforms such as Splunk, ELK, Datadog, or CloudWatch, organizations gain holistic visibility over how OpenAI is being used. Centralized monitoring enables correlation with other SaaS, cloud, and security events, allowing faster identification of malicious activity or misconfigurations. This approach also simplifies compliance audits by consolidating relevant data into a single, queryable source.
Effective monitoring isn’t just about collecting data - it’s about acting on it. Configuring alerts for anomalies such as token spikes, repeated invalid requests, or unusual geographic access patterns allows teams to respond before issues escalate. Equally important is attributing these requests back to specific users, services, or workloads, enabling targeted investigations and remediation. With clear attribution, security teams can distinguish between benign misconfigurations and genuine abuse, dramatically reducing mean time to resolution (MTTR).
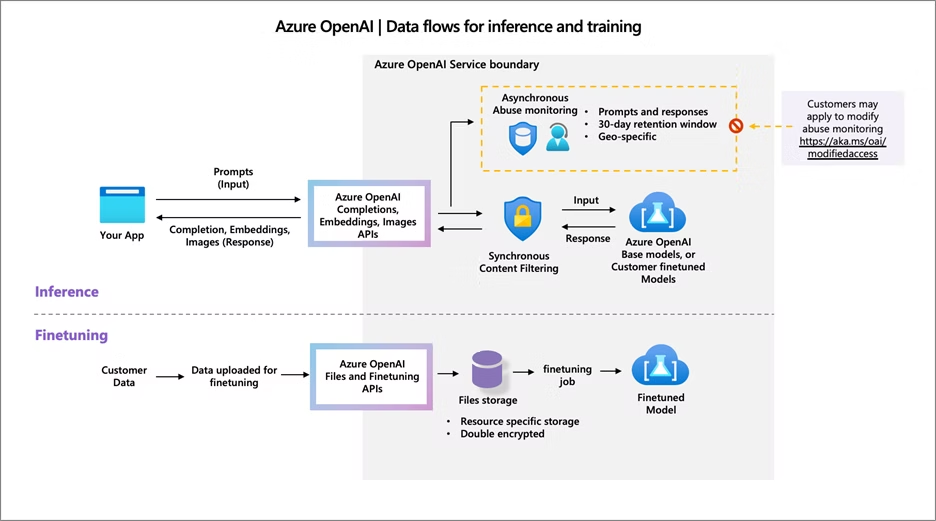
Even if inputs are controlled, outputs can still be risky, ranging from inaccurate responses to offensive or unsafe content. Enterprises must implement safeguards before exposing outputs to production users or systems.
Model updates can break workflows, shift behavior, or reduce output quality. Enterprises must treat versioning as a discipline rather than a convenience.
Like cloud platforms, AI APIs operate under a shared responsibility model. OpenAI secures the underlying infrastructure, while enterprises are responsible for secure usage, compliance, and governance.
To succeed, enterprises should document clear ownership across teams, integrate OpenAI usage into SIEM, IAM, and DLP workflows, and review governance policies regularly.


Gal is the Cofounder & CPO of Reco. Gal is a former Lieutenant Colonel in the Israeli Prime Minister's Office. He is a tech enthusiast, with a background of Security Researcher and Hacker. Gal has led teams in multiple cybersecurity areas with an expertise in the human element.

Your system prompts (the rules that govern AI behavior) are as valuable as API keys, yet many teams leave them unprotected. Treat them like sensitive code artifacts.
By safeguarding system prompts, you reduce both data leakage and model manipulation risks.
Deploying the OpenAI API safely in production requires a layered approach that balances security, compliance, and operational resilience. From secret management and network controls to monitoring, compliance enforcement, and output validation, every step in the lifecycle needs attention. With strong governance and clear shared responsibilities, enterprises can unlock the benefits of generative AI while minimizing risks, turning OpenAI into a trusted partner in their innovation journey.
Apply quotas across users, services, and global workloads with budget protections.
See Reco’s Data Exposure Controls
No, always proxy calls through a backend service that secures the key.
Learn more from Identity Threat Detection & Response
Reco maps identities, apps, and API connections to flag unauthorized or unsafe activity.
See Reco’s SSPM Workflow
.svg)

.svg)











%201.svg)









.svg)