

Incident Management in SaaS: How It Works, Challenges & Best Practices

What is Incident Management in SaaS?
Incident management in SaaS is the structured process of identifying, recording, responding to, and resolving service disruptions within a software-as-a-service environment. Its purpose is to restore normal operations as quickly as possible while minimizing impact on customers and business continuity. In SaaS, where services are delivered at scale to global users, incident management also involves proactive monitoring, clear communication, and continuous improvement of processes to address unplanned outages, performance degradations, and security issues effectively.
Incident Management vs. Problem Management
Incident management and problem management are related yet distinct disciplines. The table below highlights their differences in focus, objectives, and outcomes:
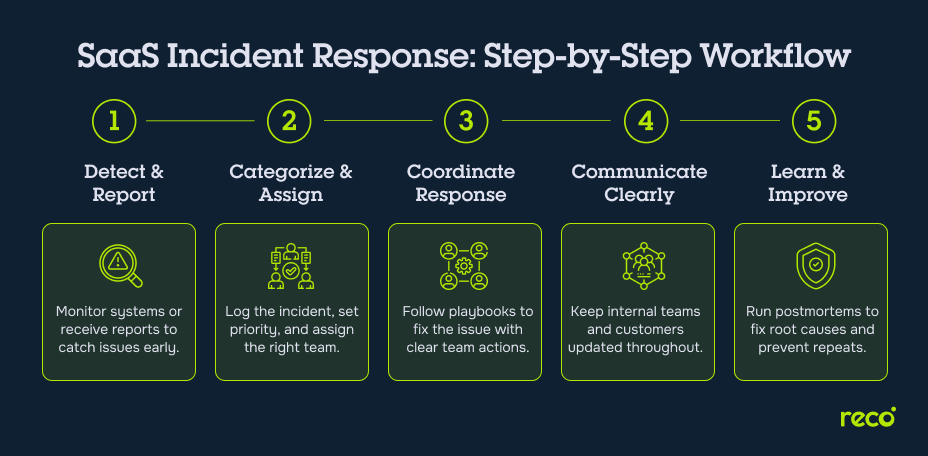
How Incident Management Works in a SaaS Environment
Incident management in a SaaS environment follows a defined sequence of processes that help teams detect, respond to, and learn from disruptions. Below are the key stages of effective incident management processes in SaaS operations:
1. Detecting and Reporting Incidents
Proactive monitoring tools and automated alerts continuously observe the SaaS infrastructure to detect anomalies, outages, or performance issues. Incidents can also be reported manually by customers or internal users through support tickets, emails, or chat systems.
2. Categorizing, Prioritizing, and Assigning Tasks
Once detected, each incident is logged in the incident management system, categorized by type (e.g., security, performance, third-party failure), prioritized based on severity and customer impact, and assigned to the appropriate response team. This ensures the most critical incidents are addressed first while maintaining accountability.
3. Executing a Coordinated Incident Response
Incident response teams rely on predefined runbooks or playbooks to guide their actions and resolve issues efficiently. Typical steps include isolating affected systems, deploying hotfixes, rolling back faulty changes, and coordinating with external vendors when necessary. Throughout the process, collaboration platforms and incident tracking software help maintain real-time communication and ensure everyone stays aligned.
4. Communicating with Internal and External Stakeholders
Clear and timely communication is critical during incidents. Internal stakeholders, such as executives and other departments, are kept updated through dashboards and reports, while customers are informed via status pages, emails, or social media about ongoing efforts and expected resolution times.
5. Postmortems and Continuous Learning
After resolution, teams conduct post-incident reviews to analyze root causes, assess response effectiveness, and document lessons learned. These insights improve future incident response processes, reduce recurrence, and enhance the overall service management posture.
Key Components of a SaaS Incident Management System
A modern SaaS incident management system combines several critical components that work in unison to detect, respond to, and resolve service disruptions effectively. Each element plays a specific role in streamlining operations, enhancing visibility, and improving team coordination:
- Centralized Incident Logging and Tracking: All incidents are recorded in a single system of record, creating a clear audit trail and enabling teams to track the incident lifecycle from detection to resolution. This improves visibility and supports reporting and compliance needs.
- Alerts, Notifications, and Escalation Rules: Automated alerts notify the appropriate personnel when incidents occur, with configurable escalation rules to ensure a timely response if the primary contact is unavailable or the situation escalates in severity.
- Automated Workflows for Triage and Resolution: Built-in workflows guide teams through consistent triage and resolution processes. Automation can prioritize incidents based on severity, route tasks to the right team, and trigger predefined remediation steps.
- Collaboration and Communication Features: Integrated chat, video, and status pages enable teams to coordinate efforts in real time and keep stakeholders informed. Seamless communication minimizes misunderstandings and speeds up incident resolution.
- Post-Incident Reviews and Reporting: Detailed reporting tools support root cause analysis and help identify recurring issues. Postmortems are documented within the system, enabling continuous improvement and knowledge sharing.
- On-Call Scheduling and Duty Rotation: Scheduling tools manage on-call rotations to ensure 24/7 coverage. They help balance workloads, prevent burnout, and guarantee that someone is always available to respond to critical incidents.
Top Incident Management Tools for SaaS Operations
The landscape of incident management tools in SaaS offers great options tailored to different organizational needs. The following overview highlights how the leading platforms help teams respond effectively.
Reco
Reco is a SaaS security platform that streamlines incident-related collaboration by bringing together conversations from Slack, Teams, and email into a single secure timeline. Reco monitors for configuration drift, identity risks, and data exposure across your SaaS environment while maintaining compliance and protecting sensitive data. Its AI agents enhance every stage of the response process. Alert Agent transforms security noise into actionable intelligence as soon as threats emerge and automatically investigates complex attacks with full context.
Identity Agent analyzes user behavior across connected apps to reveal who is accessing what and where identity threats are hiding. Remediation Plan Agent turns detection into immediate action by creating prioritized response strategies and triggering automated remediation workflows. Together, these capabilities enable effective identity threat detection and response while improving collaboration and resilience.
PagerDuty
PagerDuty is a leading incident management platform offering automated workflows that cover the entire lifecycle of an incident. It handles alert ingestion, guided response playbooks, on-call scheduling, and stakeholder communication. Its AIOps capabilities reduce noise, and its advanced analytics and postmortem features make it a strong choice for large operations that require service reliability.
incident.io
incident.io is an integrated platform that combines on-call scheduling, real-time response, and status page management. It automates the creation of incident channels, coordinates responders, and generates AI-assisted summaries directly within Slack and Teams. It is a good fit for agile engineering teams who prefer a chat-centric workflow.
Rootly
Rootly is a Slack-native platform designed to automate essential incident response steps such as triage, ticketing, and stakeholder updates. It integrates with Jira, Zoom, and Datadog to help teams manage incidents from detection through postmortem with clear timelines and well-documented actions.
Zenduty
Zenduty is a collaborative and AI-enhanced incident management platform built for SRE and support teams. It provides real-time alerts through multiple channels, including SMS, calls, email, Slack, and Teams. It also supports sophisticated on-call scheduling, escalation workflows, and AI-generated postmortems to improve team performance.
xMatters
xMatters offers adaptive service intelligence and fully customizable incident response workflows. It supports dynamic notification routing, context-aware alerts, and comprehensive analytics to help teams understand responsibilities and resolve incidents quickly and effectively.
Better Stack
Better Stack provides an integrated platform for monitoring, incident handling, and public status page management. It is developer-friendly and supports Slack-based orchestration, automated postmortem generation, and live alerts based on logs and uptime data.
Opsgenie
Opsgenie, part of the Atlassian product suite, delivers centralized alert and on-call management. It supports advanced scheduling across time zones, escalation policies, and detailed incident tracking. Opsgenie also provides integrated status pages, conference bridges, and post-incident reports designed to complement other Atlassian tools.

Gal Nakash
Cofounder & CPO at Reco

Gal is the Cofounder & CPO of Reco. Gal is a former Lieutenant Colonel in the Israeli Prime Minister's Office. He is a tech enthusiast, with a background of Security Researcher and Hacker. Gal has led teams in multiple cybersecurity areas with an expertise in the human element.

Expert Tip: Improving SaaS Incident Postmortems
In my experience managing SaaS operations, many teams treat postmortems as an afterthought, which weakens long-term improvements. A strong postmortem process turns every incident into an opportunity for resilience. Here’s how I approach it:
- Schedule Quickly: Hold the postmortem within 48 hours of resolution while details are fresh.
- Focus on Facts, Not Blame: Encourage a blameless culture where everyone feels safe contributing.
- Include All Stakeholders: Bring in engineers, support staff, and even customer success to get a full view of the impact.
- Document Publicly: Share findings and action items with the whole company to reinforce transparency and accountability.
- Track Follow-Through: Assign owners and due dates to remediation tasks so lessons learned stick.
By institutionalizing this approach, you ensure each incident strengthens your team and product instead of repeating itself.
Common Types of SaaS Incidents
SaaS environments are exposed to a wide range of incidents that can disrupt service availability, degrade performance, or compromise data. Below are the most common types of incidents teams should be prepared to handle:
Infrastructure Outages
These incidents occur when the underlying cloud infrastructure, such as servers, storage, or network components, becomes unavailable. Causes can include hardware failure, power loss, data center outages, or cloud provider disruptions. Since most SaaS platforms are built on shared infrastructure, these outages can have widespread customer impact and are often outside the direct control of the SaaS provider.
Third-Party Service Failures
SaaS applications often rely on external APIs, authentication providers, payment gateways, email services, or CDN networks. A failure in one of these third-party services can cascade into an incident for the SaaS platform itself, even though the core application remains healthy. These incidents highlight the importance of monitoring dependencies and having fallback strategies.
CI/CD Pipeline Breakdowns
Continuous integration and continuous delivery pipelines are critical for deploying updates and patches to SaaS applications. Pipeline breakdowns can result in failed deployments, rolled-back changes, or delays in delivering fixes for existing issues. Causes range from misconfigured build scripts and version conflicts to overloaded deployment systems.
Misconfigurations and Access Issues
Configuration errors are among the most common sources of SaaS incidents. Examples include incorrect DNS settings, firewall misrules, expired TLS certificates, or over-permissive access controls. Such misconfigurations can lead to outages, unintended data exposure, or blocked customer access, and are often preventable through proper change management.
Security Breaches and Data Leaks
Incidents involving unauthorized access, data exfiltration, or malicious attacks have serious consequences in SaaS. Threat actors may exploit application flaws, stolen credentials, or unsecured APIs to gain access to sensitive data. Timely detection, containment, and transparent communication are essential when responding to security breaches or data leaks to maintain customer trust and comply with regulations.
Metrics That Matter in SaaS Incident Management
Tracking the right metrics is essential for understanding how well incident management processes perform and for driving continuous improvement. These key indicators help teams measure response effectiveness, customer impact, and operational resilience.
- Mean Time to Detect (MTTD): The average time it takes to identify an incident from the moment it begins. Faster detection reflects stronger monitoring systems and reduces the window of potential damage.
- Mean Time to Respond (MTTR): The average time required to fully resolve an incident after it has been detected. This metric reveals how efficiently teams execute response plans and restore normal operations.
- Uptime and SLA Compliance: Measured as a percentage over a defined period, uptime demonstrates the reliability of the SaaS service. Compliance with Service Level Agreements (SLAs) ensures that contractual service commitments are met and customer confidence is maintained.
- Incident Volume and Recurrence Rate: Tracking how many incidents occur and how often the same type of incident reappears highlights systemic weaknesses. Reducing recurrence through thorough root cause analysis is a key goal.
- Customer Impact Score: This qualitative and quantitative measure captures how incidents affect customers, weighing factors like scope, severity, and duration. It helps prioritize efforts toward incidents that matter most to the user experience.
Best Practices for SaaS Incident Response
Implementing proven best practices helps SaaS teams minimize downtime, protect customer trust, and improve response effectiveness. The following practices are essential for a mature and resilient incident response process.
- Establish a Clear Incident Response Playbook: Document standardized workflows for common incident types, including detection, triage, escalation paths, and resolution steps. Playbooks should include predefined severity levels, communication templates, and role assignments. Regularly review and update them to reflect evolving infrastructure, security requirements, and lessons learned from postmortems.
- Automate Escalations and Notifications: Use an incident management platform or integrated workflows to automatically route incidents to the right on-call engineers based on severity, skill set, and availability. Automated notifications through multiple channels, such as SMS, email, and chat platforms, ensure that responders are alerted immediately, reducing Mean Time to Respond (MTTR).
- Train Cross-Functional Teams Regularly: Conduct ongoing training and simulation exercises to keep engineers, support staff, and stakeholders aligned on roles and responsibilities. Tabletop exercises and occasional chaos testing drills improve familiarity with tools and processes, strengthen team coordination, and help uncover gaps in readiness under realistic conditions.
- Communicate Clearly with Customers and Stakeholders: Maintain transparency during incidents by providing timely, consistent updates to customers through status pages, emails, or in-app notifications. Internal stakeholders should also receive situation reports through dashboards or briefings. Clear communication builds trust and prevents misinformation while reducing pressure on support channels.
Challenges in SaaS Incident Management
Managing incidents in SaaS environments comes with unique challenges that stem from their distributed, cloud-native nature and customer-facing scale. Teams need to be aware of these difficulties to design more resilient systems and refine their incident management processes effectively.
How to Choose the Right Incident Management Tool
Selecting the right incident management software is a critical decision for SaaS operations teams. The ideal solution should align with your workflows, improve response efficiency, and scale with your business needs. These key factors help evaluate and compare tools effectively.
Integration with Existing Stack
An effective incident management tool must integrate seamlessly with your current monitoring, logging, alerting, and communication platforms. Look for solutions with prebuilt connectors for services like Slack, Jira, AWS, Azure, Datadog, and your CI/CD pipelines. Strong API and webhook support ensures the tool can adapt to custom workflows without introducing silos.
Ease of Use for Non-Engineers
The tool should offer an intuitive interface that is accessible to non-technical stakeholders, such as support or management teams, who may need to log incidents or view status updates. Features like drag-and-drop scheduling, visual dashboards, and simplified configuration help lower the learning curve and improve adoption across departments.
Security and Compliance Capabilities
Since incident management often involves sensitive operational and customer data, strong security and SaaS compliance features are essential. Ensure the platform supports access controls, audit logs, data encryption, and compliance certifications relevant to your industry, such as SOC 2, ISO 27001, or HIPAA.
Real-Time Collaboration Features
Efficient response requires real-time collaboration between cross-functional teams. Choose a platform that supports integrated chat, incident timelines, stakeholder notifications, and contextual updates in a centralized workspace. These features help reduce confusion and accelerate resolution during high-pressure incidents.
Cost and Support Options
Finally, evaluate the total cost of ownership, including licensing, training, and maintenance. Pricing should align with your budget and scale as your team grows without penalizing usage. Additionally, consider the quality of vendor support, SLAs, and availability of documentation or community resources to ensure you can rely on help when it matters most.
How Reco Secures and Streamlines Incident Collaboration
Reco enhances SaaS incident management by combining security, context, and collaboration into a single platform. Its intelligent capabilities help teams resolve incidents faster while protecting sensitive data and maintaining compliance.
- Automatically Maps Conversations Across Slack, Teams, and Email: Reco connects to your communication channels and maps conversations into a centralized incident timeline. This ensures all relevant context and decisions are captured, even when discussions happen across different tools.
- Controls and Restricts Sensitive Info Sharing: During incident response, it is easy for sensitive information to be overshared. Reco enforces granular controls on what data is shared, preventing unauthorized disclosures while allowing teams to collaborate effectively.
- Adds Real-Time Context to Speed Up Resolution: Reco analyzes ongoing communications and surfaces real-time insights, such as who is involved, what actions have been taken, and what steps remain. This contextual awareness helps reduce duplication of effort and speeds up decision-making.
- Helps Maintain Compliance and Audit Trails: Every incident interaction is logged securely, creating a complete audit trail that supports compliance requirements. This makes it easier to meet regulatory obligations and demonstrate due diligence in postmortems.
- Makes Security and Collaboration Seamless: By bridging gaps between collaboration and security, Reco ensures teams can work quickly without compromising data protection. It creates a secure environment where engineers and stakeholders can resolve incidents with confidence.
Conclusion
Effective incident management is foundational to the success of any SaaS organization, blending technical precision, coordinated teamwork, and customer transparency. As services scale and complexities grow, investing in the right processes, tools, and best practices becomes even more critical. By understanding the challenges, tracking meaningful metrics, and leveraging purpose-built solutions like Reco, SaaS teams can confidently resolve disruptions while protecting customer trust and maintaining operational resilience.

Dvir Sasson
%201.svg)
ABOUT THE AUTHOR
Dvir is the Director of Security Research Director, where he contributes a vast array of cybersecurity expertise gained over a decade in both offensive and defensive capacities. His areas of specialization include red team operations, incident response, security operations, governance, security research, threat intelligence, and safeguarding cloud environments. With certifications in CISSP and OSCP, Dvir is passionate about problem-solving, developing automation scripts in PowerShell and Python, and delving into the mechanics of breaking things.







%201.svg)









.svg)